ARM64でptraceより2000倍以上速いシステムコールフック作った
元ネタ: https://yasukata.hatenablog.com/entry/2021/10/14/145642
せっかちな人向け
- ARM64向けの高速なシステムコールフックを作った
- マイクロベンチマークではptraceの2000倍以上、seccompの140倍程度高速
- コードはこちら: https://github.com/retrage/svc-hook
zpolineとは
USENIX ATC 2023において、zpolineというx86/Linux向けの高速なシステムコールフックが提案された[1]。これは、binary rewritingで2バイトの命令である syscallやsysenterを同じ2バイト命令であるcallq *%raxに置き換えた上で0x0のアドレスにトランポリンを設置する、というものである。
同じような仕組みを他のアーキテクチャでも実現だろうか?ということで、広く使われているARM64(以下、aarch64)向けに似たような仕組みのシステムコールフックを実装してみた。実装はGitHubで公開している:
aarch64でのbinary rewritingによるシステムコールフック
zpolineと同様の、binary rewritingによるシステムコールフックをaarch64で実現する方法を考えてみる。
aarch64におけるシステムコール
最初の前提として、一般的にaarch64でシステムコールがどのように実現しているのかをおさらいする。
aarch64では、システムコールのために svcという命令が用意されている。この命令をEL0(ユーザ空間)で実行すると、システムレジスタVBAR_ELx が指すexception vector tableに飛んで、EL1/EL2のカーネル空間に処理が移る。以上はOSに依存せず、aarch64でハードウェア的に実現している仕組みである。
次にユーザ空間からカーネル空間にどのように値が渡されるのかをみる。Linuxの場合、システムコールのcalling conventionは以下の通りである:
- x8: システムコール番号
- x0からx7: 引数
- x0: 戻り値
なお、
svc自体も即値を持つが、Linuxでは使われずに常に0が与えられているようである。
以上の情報を元に、svcを一つの命令で置き換えてシステムコールフックを実現する方法を考える。
svc置き換えの制約
aarch64では、すべての命令が4バイト固定長である。このため、命令の置き換え自体はx86と比較して単純であり、逆アセンブルせずにバイナリのパターンマッチで探索できる。
zpolineと同じようにsvcを置き換えようとした場合、コントロールフローを変更できる無条件ブランチ命令が採用候補に挙げられるだろう。無条件にブランチするaarch64の命令は以下の4種類がある:
b rel28: 符号付き28bit即値の相対ジャンプbl rel28: 符号付き28bit即値の関数呼び出し; x30に戻りアドレスを代入blr Xn: indirectに関数呼び出し; x30に戻りアドレスを代入br Xn: indirectに絶対アドレスジャンプ (なお、retはbr x30と等価なので除外する)
これらの中から利用できる命令を考えてみる。
まず、blとblrはx30レジスタを破壊するため、候補から外れる。
絶対アドレスが使えるbrを使いたいところだが、システムコールが呼ばれた時点でレジスタにどのような値が入っているかはシステムコール番号が入ったx8レジスタを除いて不明である。
ではbr x8でよいかというと、これは採用できない。なぜならば、aarch64ではpcレジスタは必ず4バイトアラインされてなければならないため、むやみにシステムコール番号のアドレスに飛べばPC misalignment exceptionが起きてしまい、処理が中断されてしまう。
このため残ったbを採用することにした。この命令は符号付き28bit即値を持ち、相対アドレスで±128MBの範囲であればどこでもジャンプ可能である。トランポリンをこの範囲に設置できれば、aarch64でもzpolineと同等のシステムコールフックが実現できる。
注意しなければならないのは、x86では無条件に0x0にトランポリンが置けるためほぼすべての場合でトランポリンが設置できるが、今回の bによる置き換えではそうではないということである。
aarch64では、相対アドレスで飛べる範囲でトランポリンが設置できるアドレスが決まってしまうため、非常に大きな実行可能領域 (256MB以上)の広い範囲で直接svcが使われていた場合には、トランポリンの設置に失敗する可能性がある。
以上より、今回は b によるsvcの置き換えを採用した。これにより、レジスタの値を破壊せずにシステムコールをフックできるようになった。しかし、まだ考えるべき点がある。
戻りアドレスを教える必要がある
bによるsvcの置き換え固有の問題として、戻りアドレスをケアしなければならない点がある。
zpolineでは callq *%rax で置き換えており、戻りアドレスが自動的にスタックにpushされるためスタックに戻りアドレスの情報が保存されている。しかし、aarch64の bでは戻りアドレスを記録せずにジャンプするため、そのまま共通のシステムコールフックにジャンプしてしまうと戻る先のアドレスがわからず処理を復帰できないという問題がある。
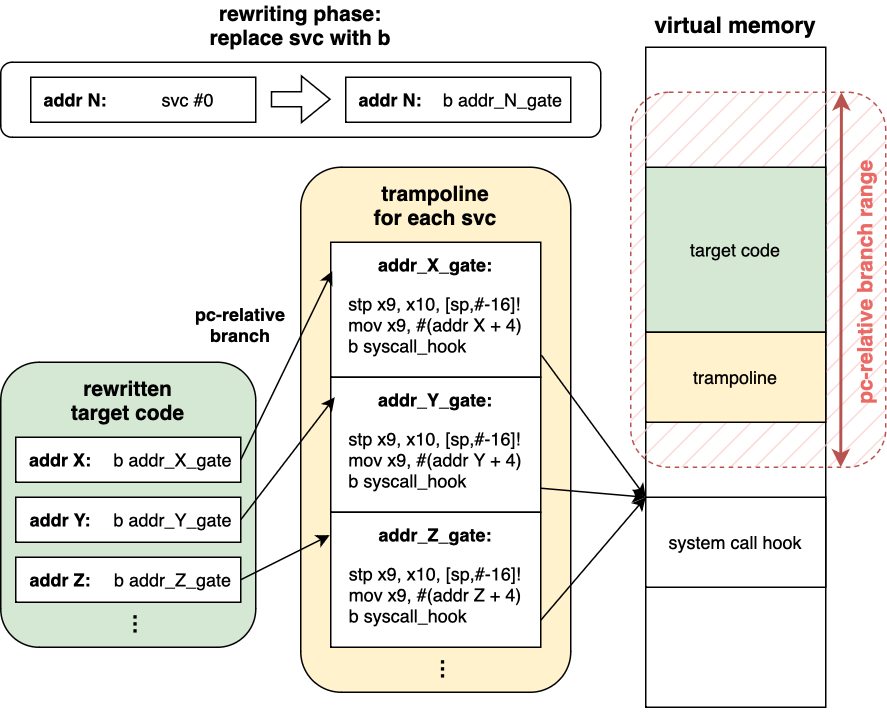
これを解決するために、各アドレスのsvcごとにトランポリンの入り口を作成し、個別に戻りアドレスを記録してから、共通のシステムコールフックに飛ぶような仕組みにした。
具体的には以下のようなコードを配置する。
stp x9, x10, [sp,#-16]!
movz x9, (#return_pc & 0xffff)
movk x9, ((#return_pc >> 16) & 0xffff), lsl 16
movk x9, ((#return_pc >> 32) & 0xffff), lsl 32
movk x9, ((#return_pc >> 48) & 0xffff), lsl 48
b do_jump_asm_syscall_hook
svc-hook設計のポイントをまとめると以下の2点がある。
bによるsvc置き換えを利用した今回のシステムコールフックでは、トランポリンコードはsvcがあるアドレスの±128MBの範囲でなければならないという制約がある。bで置き換えた場合は戻りアドレスの情報が失われるため、個別に設定する必要がある。
以下にsvc-hookの概要を図示する。
実装
zpolineをaarch64に移植できないか、というところから始まったため、基本的な作りはzpolineに準拠している。一方で、トランポリンの設置方法など設計から大きく異なる部分もある。特に、zpolineではx86のコードをディスアセンブルして syscallとsysenterを見つけていたが、aarch64ではディスアセンブルせずにバイナリのパターンマッチで十分であった。これにより、binutilsへの依存がなくなり、読み込み時のパフォーマンスもある程度向上しているはずである。
性能
getpid() を1000回実行し1回あたりの平均時間を比較した。
比較対象は以下の通りである:
- native: フックなし
- ptrace: ptraceによるシステムコールフック
- brk:
brk(ソフトウェアブレークポイント)への書き換えによるフック - seccomp:
getpid()のフック - svc-hook: 今回作成したもの
- ldpreload: LD_PRELOADによる
getpid()の置き換え
なお、今回はSyscall User Dispatch (SUD)はカーネルが対応していなかったため除外した。 native以外の各フックではダミーの値を返し、システムコールフックのオーバーヘッドを比較できるようにした。実験環境はRockchip RK3588, Linux 6.1.25 (Ubuntu 22.04.4 LTS)である。 結果は以下の通りである:
| getpid(nsec) | |
|---|---|
| native | 731 |
| ptrace | 47249 |
| brk | 2760 |
| seccomp | 3001 |
| svc-hook | 21 |
| ldpreload | 7 |
結果としてはptraceの2200倍程度、brkの130倍程度、seccompの140倍程度高速のようである。ベンチマークのコードを書いたのは自分なのであまり信用していないが、かなり高速であることがわかる。
まとめ
x86向けのzpolineと同じbinary rewritingによるシステムコールフックをaarch64向けに実装した。マイクロベンチマークではptraceよりも2200倍程度高速であった。実装はGitHubで公開している。
謝辞
本記事の執筆にあたり、安形憲一さまと田崎創さまには、貴重な助言をいただきました。ここに感謝の意を表します。
参考文献
[1] https://www.usenix.org/conference/atc23/presentation/yasukata